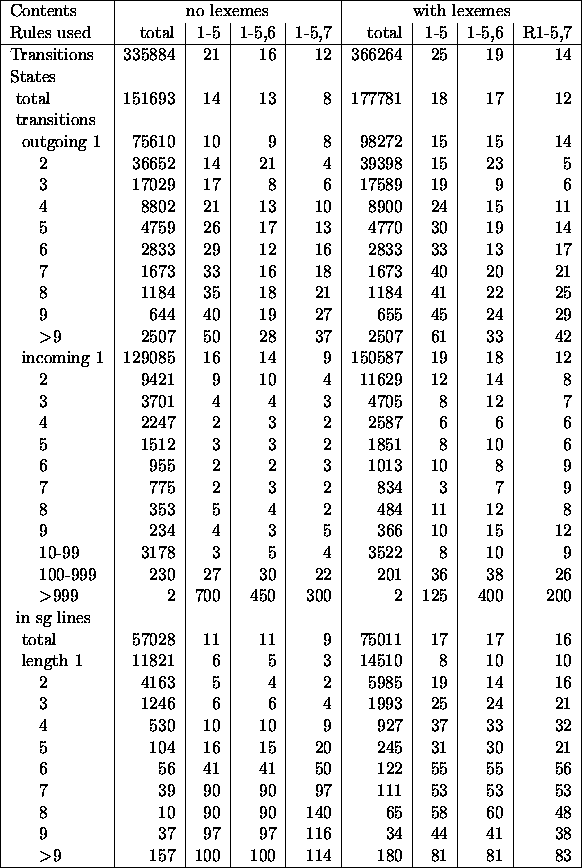
Table 5.1: Impact of rules on statistics for a French Dictionary
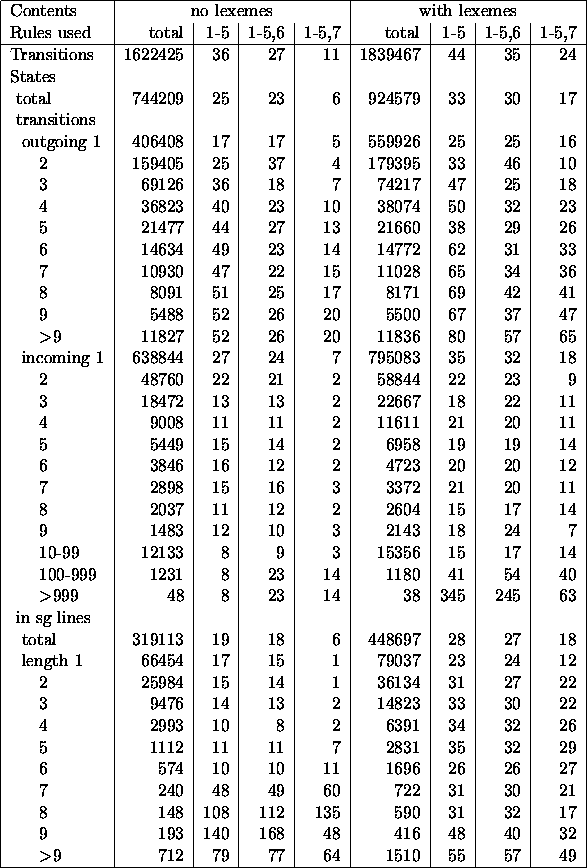
Table 5.2: Impact of rules on statistics for a Polish
dictionary
The algorithms were tested on French and Polish data. For Polish, prefixes that had impact on categories were removed from the automata without lexemes to make possible the comparison with French. For the rule R6, there had to be twice as much frequent transitions than the others to trigger the rule. For the rule R7, the limit on the number of first states was 2. There was no lower limit on the number of states to be removed by R7. Table 5.1 shows the automata for French, and table 5.2 - for Polish.
States with one outgoing transition constitute about half of all states, and those with one incoming transition - more than 80%. States that have only one incoming, and one outgoing transition form single lines.
The number given under the heading ``total'' are absolute numbers. Those under headings listing rules used are given as percents of numbers for an automaton for which no rules were applied. The standard procedure, i.e. the rules R1 ...R5 reduces the automaton to 36 to 21 percent of its original size. The effectiveness of those rules is the best for French without lexemes, and the worst for Polish with lexemes. This is because the French data is much more regular. The French dictionary was built from a two-level morphology, the Polish one - from a source listing irregular roots for all entries, and thus more prone to errors. Polish flexion is much more irregular (or rich) than the French one. And last, but not least, the Polish dictionary contained 1,757,557 inflected forms, and the French one - only 235,566. Lexemes introduce new irregularities, e.g. from irregular words.
Rules R1 ...R5 operate most effectively on states with few outgoing transitions. Adding R6 preserves that pattern, though two peaks emerge: for states with 2, and with 5 transitions. They are the result of the threshold used in the rule. There must be at least two frequent transitions for one infrequent to trigger the rule, so the states that satisfied the condition and had 3, 4, or more transitions originally, now have only 2. The second peak comes from a situation when there are are two unfrequent transitions. It is worth noticing that R6 does not introduce extra reduction of states (the reduction that does occur is the result of making some states equivalent); only transitions are cut off.
The last rule - R7 - is the most effective in terms of lexicon size reduction. While still doing better with states with fewer outgoing transitions, it cuts the number of other states much better than other methods. Both the number of states, and the number of transitions in the automaton are reduced significantly.
The size of the automaton depends on the number of different features in the tagset. The richer the tagset, the bigger the automaton. The tagset used in our experiments was verbose.
For algorithms using the guesser constructed according to the rules described in this chapter, and an evaluation of the results, see section 6.3.3.